Memory Management With Zig¶
This post is aimed at people who come from languages with automatic garbage collection and want to get a sense for how to approach memory management in a lower level language. I’ll be using Zig (and a bit of Python) to demonstrate, but the concepts apply to C and other languages where you have to care if your data is going on the stack or the heap.
This is related to the post on pointers in Zig, and for a similar audience, but here we’re going to look more at the memory management aspects than the syntax and what it means.
If you want to follow along with the code for this, the snippets shown are taken from more complete files available on sourcehut.
RPN Calculators¶
In order to look at how memory management works, we’re going to use a concrete application. Reverse polish notation calculators are frequently used to teach basic concepts in computer science, like how stacks work. Conveniently, a stack is a data structure that grows and shrinks over its lifetime. So we’re going to write an RPN calculator in Zig, and use it as a vehicle for exploring how to implement dynamic data structures.
Inconveniently, the call stack is a place where memory lives and has a frustratingly similar name. In the interest of clarity, I’ll try to always refer to the call stack as the call stack or execution stack. If I’m talking about a stack and don’t qualify it, I mean the data structure that holds values for the calculator.
Before looking at it in Zig, though, we’re going to look at a simple Python implementation of an RPN calculator and briefly cover what it does. Ours will be a simple four-function calculator. Numbers will be pushed on a stack, and operators will pop 2 numbers off, apply the operation, and push the result back on.
Here’s a Python implementation of the core of the calculator.
ops = {
'+': lambda a, b: a + b,
'-': lambda a, b: a - b,
'*': lambda a, b: a * b,
'/': lambda a, b: a / b,
}
def rpn(cmd: str, vals: list[float]):
val = str2float(cmd) # Returns None if it isn't a float.
if val is not None:
vals.append(val)
return None
op = ops[cmd]
b = vals.pop()
a = vals.pop()
vals.append(op(a, b))
return vals[-1]
Let’s break it down by all the memory it uses. We’ll start with the
local variables. Several local variables are instantiated in this
function, and cease to matter when it returns: val, op, a,
and b. These can all live on the execution stack, allocated by the
runtime when the function starts and freed when it returns.
Next up are the arguments. The first one, cmd, is just a string to
be interpreted. It’s either a number, in which case it’s pushed on the
stack, an operation, in which case it’s turned into a function, or
something else, which causes an error to bubble up to the caller.
The second argument, though, is the stack we’re using to do our work. This stack is lengthened and shortened over the life of the program. Since it’s changing size at runtime, it’s an appropriate thing to use with dynamic memory.
Zig Though¶
Python manages our memory for us, though, and we’re here to talk about doing that manually. So let’s take a look at what a stack looks like in Zig. Of course, the good way to implement a stack in Zig is probably to use std.ArrayList or std.SegmentedList. But we’re here to learn about things, not to write production quality software. So instead, we’ll write our own linked list implementation.
Allocators?¶
A brief note on allocators: Zig’s philosophy of no hidden allocations
is great, but it tends to make you think that you have to become an
expert in all the different allocators in order to use Zig well. In
most unmanaged languages, I just call malloc and never worry about
what the allocator is doing under the hood. Zig feels different,
because it gives us a choice to make here. That’s ok though, because
we’re going to choose to use the default. You don’t have to become an
expert in heaps or arena allocators to use Zig any more than you have
to know everything about ORMs and databases to use
Django. std.heap.GeneralPurposeAllocator is good enough for our
purposes, and probably the vast majority of allocation needs you’ll
ever have. However, if you do want to learn more about allocators,
Benjamin Feng gave a talk about some of the simpler ones and the search
term you want for the other ones is heap allocator.
That said, we can write our Stack implementation using idiomatic Zig
and have it accept an Allocator as an argument. Problem deferred.
A Stack¶
This isn’t a tutorial on generics, so I’m going to make a very bad stack that only holds 64-bit floats. Zig’s generic support is probably among the nicest I’ve ever seen (see also: D) but it’s not for us today. For now the focus is on memory management. To that end, our stack will be built out of everyone’s favorite data structure: a linked list. Here’s a definition of just the data parts:
pub const Stack = struct {
const Self = @This();
pub const Node = struct {
next: ?*Node = null,
data: f64,
};
head: ?*Node = null,
};
Our stack interface is going to have the same functions we used in the
Python RPN implementation: push, pop, and peek. Let’s look
at how those might be implemented in Zig.
const std = @import("std");
const Allocator = std.mem.Allocator;
pub const Stack = struct {
const Self = @This();
pub const Node = struct {
next: ?*Node = null,
data: f64,
};
head: ?*Node = null,
allocator: Allocator,
pub fn push(self: *Self, val: f64) !void {
const next: ?*Node = self.head;
var new: *Node = try self.allocator.create(Node);
new.next = next;
new.data = val;
self.head = new;
}
pub fn pop(self: *Self) ?f64 {
const popped: *Node = self.head orelse return null;
defer self.allocator.destroy(popped);
self.head = popped.next;
return popped.data;
}
pub fn peek(self: *Self) ?f64 {
const next: *Node = self.head orelse return null;
return next.data;
}
pub fn init(allocator: Allocator) Self {
return Self{
.head = null,
.allocator = allocator,
};
}
pub fn deinit(self: *Self) void {
while (self.pop()) |_| {}
}
};
As you can see, we’ve got some allocation going on. The peek
function doesn’t change the size of the data structure, but push
and pop both do. When we want to add a node to the list, we have
to get some space to put it in, and after reading the value in pop
it’s important to release the memory.
A Tangent¶
This is a good time to talk about what the allocator is actually doing. The std.mem.Allocator type provides us with an interface that has a lot of surface area, but we can focus on the important parts. The Allocator interface requires anything that implements it to expose a way to get memory and a way to give it back. Some allocators don’t care that you’ve given the memory back, but that’s not important.
The main function that user code will call from an Allocator is
create(self: Allocator, comptime T: type) Error!*T. It gets enough
memory to hold a T and hands a pointer back to the caller. Its
counterpart, destroy(self: Allocator, ptr: anytype) void, gives
the memory back. Note that destroy never fails. That’s a Zig
thing. Freeing resources doesn’t fail.
There’s also alloc and free, which you can use to get and
release an array of a data type, but for our purposes create and
destroy will suffice.
So what does an allocator do? It has some memory, and it keeps track of which bits are being used and which bits are free. When someone asks, it checks if there’s enough free memory to fulfill the request hands out a pointer to it if there is.
Note that alloc returns an error or a pointer. There’s no ? in
the type, so it’s not an optional pointer. So if it didn’t fail with
an error, you now have a pointer to the thing you requested.
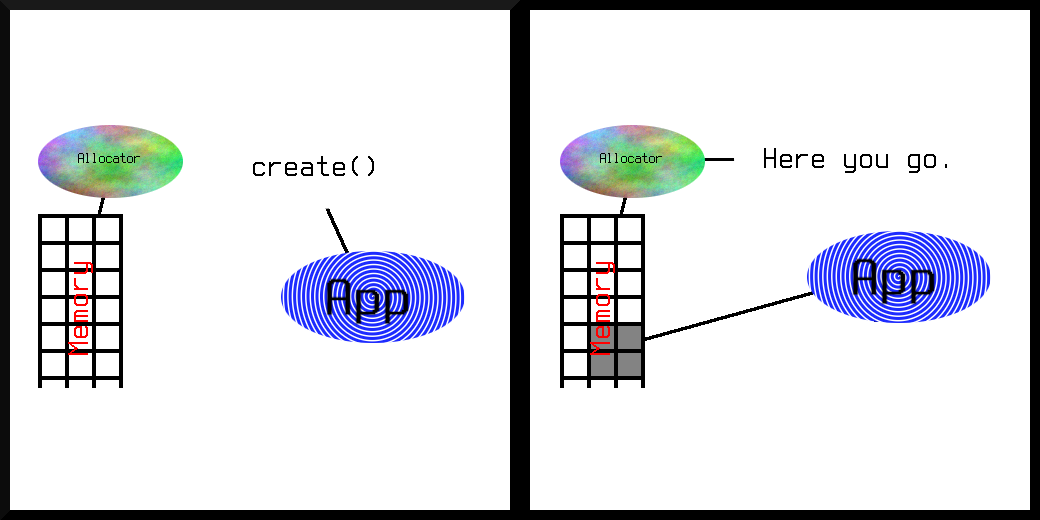
When you’re done with the memory the allocator gave you, it’s polite
to give it back. When writing libraries where you don’t know which
allocator will be used, it’s very important to pair every call to
alloc with one to destroy. That tells the allocator you’re
done with it and it may reuse the memory you had for someone else.
Allocators??¶
When I said earlier that we don’t have to think about which allocator
to use, because we’re always just going to choose the default, I lied
a little. I’ve written a lot of C, and almost never used anything but
the default malloc in production. However, in tests, I very frequently
use memcheck which replaces the default heap
allocator. Zig conveniently has std.testing.allocator, which we
can use to test our stack implementation. So that’s what we’ll do.
Stack Testing¶
Here’s a little test to ensure that our stack is working
properly. Note that if we leave the last 2 calls to pop out, or if
we delete the defer self.allocator.destroy(popped) line, we’ll get
a useful error from the testing allocator about leaking memory.
const testing = std.testing;
const alloc = std.testing.allocator;
test "Create, push, pop" {
var stack: Stack = Stack.init(alloc);
try std.testing.expectEqual(@as(?f64, null), stack.peek());
try std.testing.expectEqual(@as(?f64, null), stack.pop());
try stack.push(2.5);
try std.testing.expectEqual(@as(?f64, 2.5), stack.peek());
try stack.push(3.5);
try std.testing.expectEqual(@as(?f64, 3.5), stack.peek());
try std.testing.expectEqual(@as(?f64, 3.5), stack.pop());
try std.testing.expectEqual(@as(?f64, 2.5), stack.peek());
try std.testing.expectEqual(@as(?f64, 2.5), stack.pop());
try std.testing.expectEqual(@as(?f64, null), stack.peek());
try std.testing.expectEqual(@as(?f64, null), stack.pop());
}
Application¶
Now we have a working stack implementation, it’s time to wrap that RPN calculator around it. We can pretty closely follow the Python implementation.
const std = @import("std");
const Stack = @import("stack.zig").Stack;
fn str2f64(s: []const u8) ?f64 {
return std.fmt.parseFloat(f64, s) catch return null;
}
fn add(a: f64, b: f64) f64 {
return a + b;
}
fn sub(a: f64, b: f64) f64 {
return a - b;
}
fn mul(a: f64, b: f64) f64 {
return a * b;
}
fn div(a: f64, b: f64) f64 {
return a / b;
}
fn rpn(cmd: []const u8, vals: *Stack) !?f64 {
if (str2f64(cmd)) |val| {
try vals.push(val);
return null;
}
const b = vals.pop().?;
const a = vals.pop().?;
const result = switch (cmd[0]) {
'+' => add(a, b),
'-' => sub(a, b),
'*' => mul(a, b),
'/' => div(a, b),
else => return error.BadOp,
};
try vals.push(result);
return vals.peek();
}
As you can see, we’ve got the same val, a, and b execution
stack variables. The transition to a less functional style turns
op into result, but overall it’s pretty clearly doing the same
thing. Note that the allocation is all handled by the data
structure. The calculator code doesn’t need to worry about when memory
is allocated or freed. It’s on the caller to make sure that the
Stack is properly initialized and cleaned up.
Of course, this implies the existence of a caller. Let’s add a test
that uses the calculator to do some math. The test, as the owner of
the stack, is responsible for ensuring that it has its has init
and deinit functions called.
const testing = std.testing;
const alloc = std.testing.allocator;
test "Reverse some polish notations." {
var stack: Stack = Stack.init(alloc);
defer stack.deinit();
try testing.expectEqual(@as(?f64, null), try rpn("3.5", &stack));
try testing.expectEqual(@as(?f64, null), try rpn("5.5", &stack));
try testing.expectEqual(@as(?f64, 9.0), try rpn("+", &stack));
try testing.expectEqual(@as(?f64, null), try rpn("83", &stack));
try testing.expectEqual(@as(?f64, null), try rpn("3", &stack));
_ = try rpn("/", &stack);
try testing.expectEqual(@as(?f64, 249.0), try rpn("*", &stack));
try testing.expectEqual(@as(?f64, null), try rpn("49", &stack));
try testing.expectEqual(@as(?f64, 200.0), try rpn("-", &stack));
}
Memories¶
Let’s take a look at what the memory looks like over the lifetime of
this final program. We start at the top of the call stack, allocating
a Stack object.
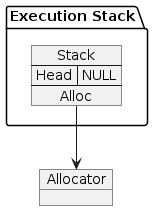
Stack.init(alloc)¶
As you can see, the only variable on the execution stack here is
stack. After being initialized, its head pointer is null and
its allocator points to the testing allocator.
The next thing it does is push 3.5 and onto the stack. Let’s look
at what the memory looks like after that.
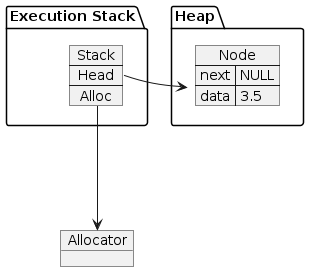
rpn(“3.5”, &stack)¶
When we called vals.push(val) inside the rpn function, the
Stack called Allocator.create. This gave us a pointer to enough
uninitialized memory to hold one Node. Then push filled it in
and stuck the address in the Stack’s head field. Since the
testing allocator uses the general purpose allocator under the hood,
the memory it gave us was on the heap. Now we’ll skip ahead a bit in
the test to show what the memory looks like after a few things have
been put on the stack. This is the program’s state right before the
/ is sent:
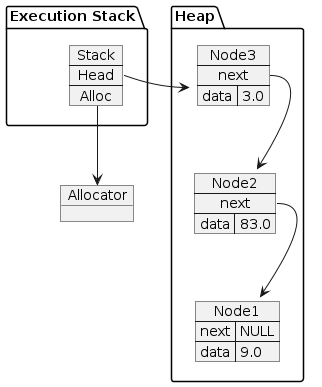
rpn(3, &stack)¶
The subsequent calls to push resulted in more memory allocated on
the heap. This memory is not guaranteed to be contiguous (one reason
not to use linked lists on modern computers) but it’s all been given
to us by the allocator.
When we get to the end of the test, the defer stack.deinit() runs
and we give all the heap memory back to the allocator by way of
pop’s call to self.allocator.destroy. In the instant before
our call stack frame is reclaimed, the memory looks just like it did
at the start.
stack.deinit()¶
Concluding¶
Memory management isn’t fundamentally all that hard. Just think about your data structures and how they behave at runtime and you’ll be able to decide where everything ought to live.
You may have noticed that the singly linked list implementation in
Zig’s standard library actually doesn’t include functions for
allocating new nodes. That’s because in the general case you might
want to store the whole list using nodes that are already on the call
stack, or you could want to store a list of structs that themselves
have pointers to other data. Managing that is properly done by a
higher level part of the system. If we had implemented our stack of
floats using std.SinglyLinkedList, we still would have had to wrap
it up in something that allocates and frees.
As I said at the start, though, we probably would have been better
served by a std.ArrayList or std.SegmentedList. Our stack
doesn’t really need to give back its memory every time it shrinks a
little.
Resource Management¶
Another thing I want to mention: memory is not the only resource we
manage when developing software. I write a lot of embedded code, and
sometimes I have to acquire exclusive access to some piece of
hardware, do something with it, then leave it in a good state. The
tools Zig gives us for cleaning up when we’re done with memory
(defer and errdefer) are useful for making sure the hardware
is left in a good state when we’re done with it. They can also be used
to do things like releasing mutexes, closing files, and finishing
database transactions.
This post uses a little bit of Python, and while Python manages memory
for you, it also gives you tools like try/finally and with
to do resource management. If you think of memory as just another
resource to be managed, you might have an easier time in both managed
and unmanaged languages.
Acknowledgement¶
Thanks to Barry Penner for encouraging me to write this and reviewing a draft.